
International
ADVANCED AND APPLIED SCIENCES
EISSN: 2313-3724, Print ISSN: 2313-626X
Frequency: 12
![]()
Volume 11, Issue 5 (May 2024), Pages: 177-185

----------------------------------------------
Original Research Paper
Multi-label text classification on unbalanced Twitter with monolingual model and hyperparameter optimization for hate speech and abusive language detection
Author(s):
Affiliation(s):
1Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, Saudi Arabia
2School of Computing and Informatics, Universiti Teknologi Brunei, Bandar Seri Begawan, Brunei
3Faculty of Information Technology, Universitas Budi Luhur, Jakarta, Indonesia
Full text

* Corresponding Author.
 Corresponding author's ORCID profile: https://orcid.org/0000-0003-2772-9427
Corresponding author's ORCID profile: https://orcid.org/0000-0003-2772-9427
Digital Object Identifier (DOI)
https://doi.org/10.21833/ijaas.2024.05.019
Abstract
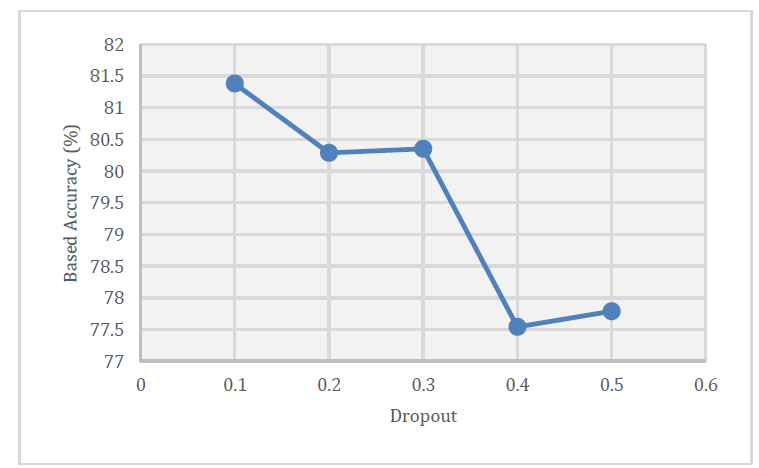
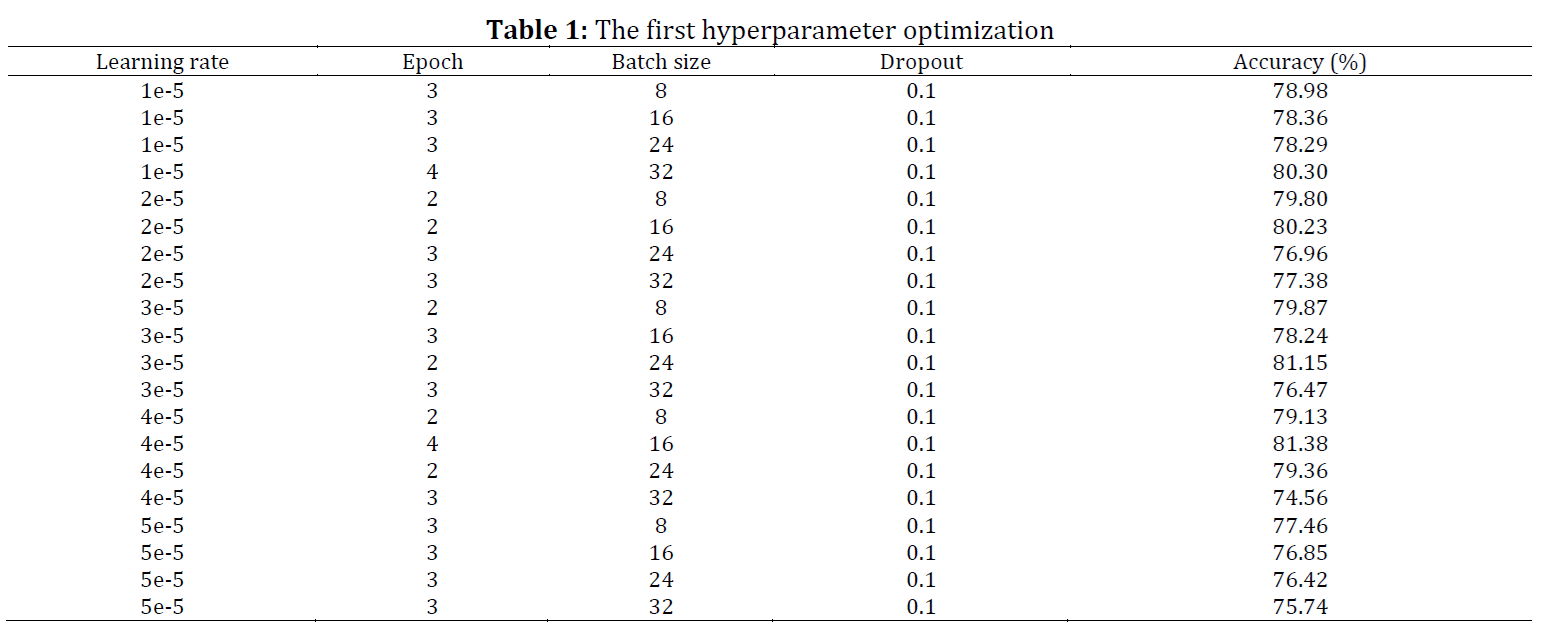
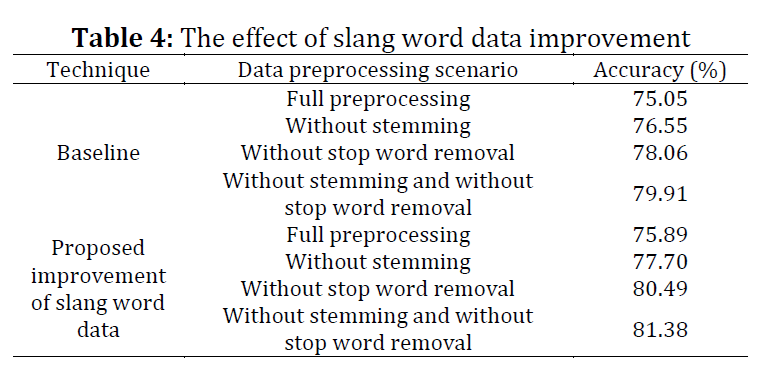
The increase in hate speech and abusive language on social media leads to uncomfortable interactions among users. Many datasets available publicly that address hate speech and abusive language are not balanced, particularly those from Indonesian Twitter. To develop a more effective classification model that also considers minority classes, we needed to optimize the hyperparameters of a monolingual model, use four different data preprocessing scenarios, and improve the treatment of slang words. We assessed the model's effectiveness by its accuracy, achieving 81.38%. This result came from optimizing hyperparameters, processing data without stemming and removing stop words, and enhancing the slang word data. The optimal hyperparameters were a learning rate of 4e-5, a batch size of 16, and a dropout rate of 0.1. However, using too much dropout can decrease the model’s performance and its ability to predict less common categories, such as physical- and gender-related hate speech.
© 2024 The Authors. Published by IASE.
This is an
Keywords
Hate speech, Abusive language, Imbalanced dataset, Multi-label text classification, Hyperparameter optimization
Article history
Received 19 December 2023, Received in revised form 2 May 2024, Accepted 5 May 2024
Acknowledgment
This research work was funded by Institutional Fund Projects under grant no. (IFPIP: 1192-611-1443). The authors gratefully acknowledge the technical and financial support provided by the Ministry of Education and King Abdulaziz University, DSR, Jeddah, Saudi Arabia.
Compliance with ethical standards
Conflict of interest: The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Citation:
Alzahrani AA, Bramantoro A, and Permana A (2024). Multi-label text classification on unbalanced Twitter with monolingual model and hyperparameter optimization for hate speech and abusive language detection. International Journal of Advanced and Applied Sciences, 11(5): 177-185
Figures
Fig. 1 Fig. 2 Fig. 3 Fig. 4 Fig. 5
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Tables
Table 1 Table 2 Table 3 Table 4
{kind=link}
{kind=link}
{kind=link}
{kind=link}
----------------------------------------------
References (24)
- Alfina I, Mulia R, Fanany MI, and Ekanata Y (2017). Hate speech detection in the Indonesian language: A dataset and preliminary study. In the International Conference on Advanced Computer Science and Information Systems, IEEE, Bali, Indonesia: 233-238. https://doi.org/10.1109/ICACSIS.2017.8355039 [Google Scholar] PMid:35875654 PMCid:PMC9299239
- Bramantoro A and Virdyna I (2022). Classification of divorce causes during the COVID-19 pandemic using convolutional neural networks. PeerJ Computer Science, 8: e998. https://doi.org/10.7717/peerj-cs.998 [Google Scholar]
- El Kafrawy P, Mausad A, and Esmail H (2015). Experimental comparison of methods for multi-label classification in different application domains. International Journal of Computer Applications, 114: 19. https://doi.org/10.5120/20083-1666 [Google Scholar]
- Fernández A, García S, Galar M, Prati RC, Krawczyk B, and Herrera F (2018). Learning from imbalanced data sets. Springer, Berlin/Heidelberg, Germany. https://doi.org/10.1007/978-3-319-98074-4 [Google Scholar]
- Hana KM, Al Faraby S, and Bramantoro A (2020). Multi-label classification of Indonesian hate speech on Twitter using support vector machines. In the International Conference on Data Science and Its Applications, IEEE, Bandung, Indonesia: 1-7. https://doi.org/10.1109/ICoDSA50139.2020.9212992 [Google Scholar]
- Hendrawan R, Adiwijaya, and Al Faraby S (2020). Multilabel classification of hate speech and abusive words on Indonesian Twitter social media. In the International Conference on Data Science and Its Applications, IEEE, Bandung, Indonesia: 1-7. https://doi.org/10.1109/ICoDSA50139.2020.9212962 [Google Scholar]
- Hinton GE, Srivastava N, Krizhevsky A, Sutskever I, and Salakhutdinov RR (2012). Improving neural networks by preventing co-adaptation of feature detectors. ArXiv Preprint ArXiv:1207.0580. https://doi.org/10.48550/arXiv.1207.0580 [Google Scholar]
- Ibrohim MO and Budi I (2019). Multi-label hate speech and abusive language detection in Indonesian Twitter. In the 3rd Workshop on Abusive Language Online, Association for Computational Linguistics, Florence, Italy: 46-57. https://doi.org/10.18653/v1/W19-3506 [Google Scholar]
- Johnson JM and Khoshgoftaar TM (2019). Survey on deep learning with class imbalance. Journal of Big Data, 6: 27. https://doi.org/10.1186/s40537-019-0192-5 [Google Scholar]
- Kingma DP and Ba JL (2015). Adam: A method for stochastic optimization. ArXiv Preprint ArXiv:1412.6980. https://doi.org/10.48550/arXiv.1412.6980 [Google Scholar]
- Kovács G, Alonso P, and Saini R (2021). Challenges of hate speech detection in social media: Data scarcity, and leveraging external resources. SN Computer Science, 2: 95. https://doi.org/10.1007/s42979-021-00457-3 [Google Scholar]
- Li H, Li J, Guan X, Liang B, Lai Y, and Luo X (2019). Research on overfitting of deep learning. In the 15th International Conference on Computational Intelligence and Security, IEEE, Macao, China: 78-81. https://doi.org/10.1109/CIS.2019.00025 [Google Scholar]
- Makruf M, Bramantoro A, Alyamani HJ, Alesawi S, and Alturki R (2021). Classification methods comparison for customer churn prediction in the telecommunication industry. International Journal of Advanced and Applied Sciences, 8(12): 1-8. https://doi.org/10.21833/ijaas.2021.12.001 [Google Scholar]
- Niemann M, Riehle DM, Brunk J, and Becker J (2020). What is abusive language? Integrating different views on abusive language for machine learning. In: Grimme C, Preuss M, Takes F, and Waldherr A (Eds.), Multidisciplinary international symposium on disinformation in open online media: 59-73. Springer International Publishing, Cham, Switzerland. https://doi.org/10.1007/978-3-030-39627-5_6 [Google Scholar]
- Prabowo FA, Ibrohim MO, and Budi I (2019). Hierarchical multi-label classification to identify hate speech and abusive language on Indonesian Twitter. In the 6th International Conference on Information Technology, Computer and Electrical Engineering, IEEE, Semarang, Indonesia: 1-5. https://doi.org/10.1109/ICITACEE.2019.8904425 [Google Scholar]
- Pratondo A and Bramantoro A (2022). Classification of Zophobas morio and Tenebrio molitor using transfer learning. PeerJ Computer Science, 8: e884. https://doi.org/10.7717/peerj-cs.884 [Google Scholar] PMid:35494845 PMCid:PMC9044276
- Putra IF and Purwarianti A (2020). Improving Indonesian text classification using multilingual language model. In the 7th International Conference on Advance Informatics: Concepts, Theory and Applications, IEEE, Tokoname, Japan: 1-5. https://doi.org/10.1109/ICAICTA49861.2020.9429038 [Google Scholar] PMid:32268239
- Ramyachitra D and Manikandan P (2014). Imbalanced dataset classification and solutions: A review. International Journal of Computing and Business Research, 5(4): 1-29. [Google Scholar]
- Saputri MS, Mahendra R, and Adriani M (2018). Emotion classification on Indonesian Twitter dataset. In the International Conference on Asian Language Processing, IEEE, Bandung, Indonesia: 90-95. https://doi.org/10.1109/IALP.2018.8629262 [Google Scholar]
- Srivastava N, Hinton G, Krizhevsky A, Sutskever I, and Salakhutdinov R (2014). Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1): 1929-1958. [Google Scholar]
- Srividhya V and Anitha R (2010). Evaluating preprocessing techniques in text categorization. International Journal of Computer Science and Application, 47(11): 49-51. [Google Scholar]
- Warner W and Hirschberg J (2012). Detecting hate speech on the world wide web. In the 2nd Workshop on Language in Social Media, Association for Computational Linguistics, Montreal, Canada: 19-26. [Google Scholar]
- Wilie B, Vincentio K, Winata GI, Cahyawijaya S, Li X, Lim ZY, Soleman S, Mahendra R, Fung P, Bahar S, and Purwarianti A (2020). IndoNLU: Benchmark and resources for evaluating Indonesian natural language understanding. In the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, Suzhou, China: 843–857. [Google Scholar]
- Winata GI and Khodra ML (2015). Handling imbalanced dataset in multi-label text categorization using bagging and adaptive boosting. In the International Conference on Electrical Engineering and Informatics, IEEE, Denpasar, Indonesia: 500-505. https://doi.org/10.1109/ICEEI.2015.7352552 [Google Scholar]